Blog Post
Why AI Coding Agents Fail Even When the Code Works and How Superpowers Fixes It

If you’ve deployed AI coding assistants at enterprise scale, you’ve probably seen this pattern: the agent generates working code within seconds, merges it to your branch, and then you discover it used the wrong library, created files in unexpected locations, or quietly skipped two of your actual requirements.
The frustrating part? The code compiles. It even runs. It’s just not what you asked for.
I’ve spent the last year watching enterprise teams wrestle with this exact problem, and what I’ve learned is counterintuitive: the issue isn’t model capability. It’s workflow discipline.
Most organizations are treating AI coding agents like really smart autocomplete tools. What they actually need is a behavioral framework that makes agents work like senior engineers who know when to ask questions before writing code.
The Core Problem: Agents Are Trained to Generate, Not to Engineer
Every experienced developer knows the first instinct when handed a new feature request should be to clarify requirements, explore alternatives, and validate the approach. AI agents do the opposite. They start coding immediately.
Feed Claude or Copilot a feature request, and it will pick a library without asking if you have a preferred stack, create files without confirming directory structure, and make architectural decisions in silence. The output is syntactically correct but architecturally misaligned.
This is not a bug in the model. It’s a missing contract layer between what the agent can do and how it should behave in a structured engineering environment.
The open source Superpowers framework (GitHub repo, which has accumulated over 157,000 GitHub stars as of April 2026) was built specifically to solve this problem. What makes it interesting from an architecture perspective is not that it’s a new model or IDE plugin. It’s a behavior control plane that sits on top of existing agents and enforces workflow discipline through composable skills.
What Superpowers Actually Does
Superpowers works by injecting a set of SKILL.md files into the agent’s operating context. These are structured behavioral guides the agent reads before taking action. Think of them as executable playbooks.
Instead of letting the agent improvise a development approach each time, you give it a library of reusable patterns: how to brainstorm before coding, how to decompose work into testable chunks, how to verify output before marking tasks complete, how to request code review with the right context.
The result is an agent that behaves more like a mid-level engineer following a defined process than a generative tool operating in freeform mode.
It installs as an npm package and works across Claude Code, Cursor, Codex, Gemini CLI, OpenCode, and GitHub Copilot CLI. The skills layer is compatible with any tool that reads CLAUDE.md configuration files at session start.
The real insight here is token efficiency. When an agent references a pre-written skill instead of reasoning through an approach from scratch every time, it burns fewer tokens and produces more consistent output. This matters at enterprise scale where token cost and output variability are both operational risks.
The Seven Stage Engineering Workflow
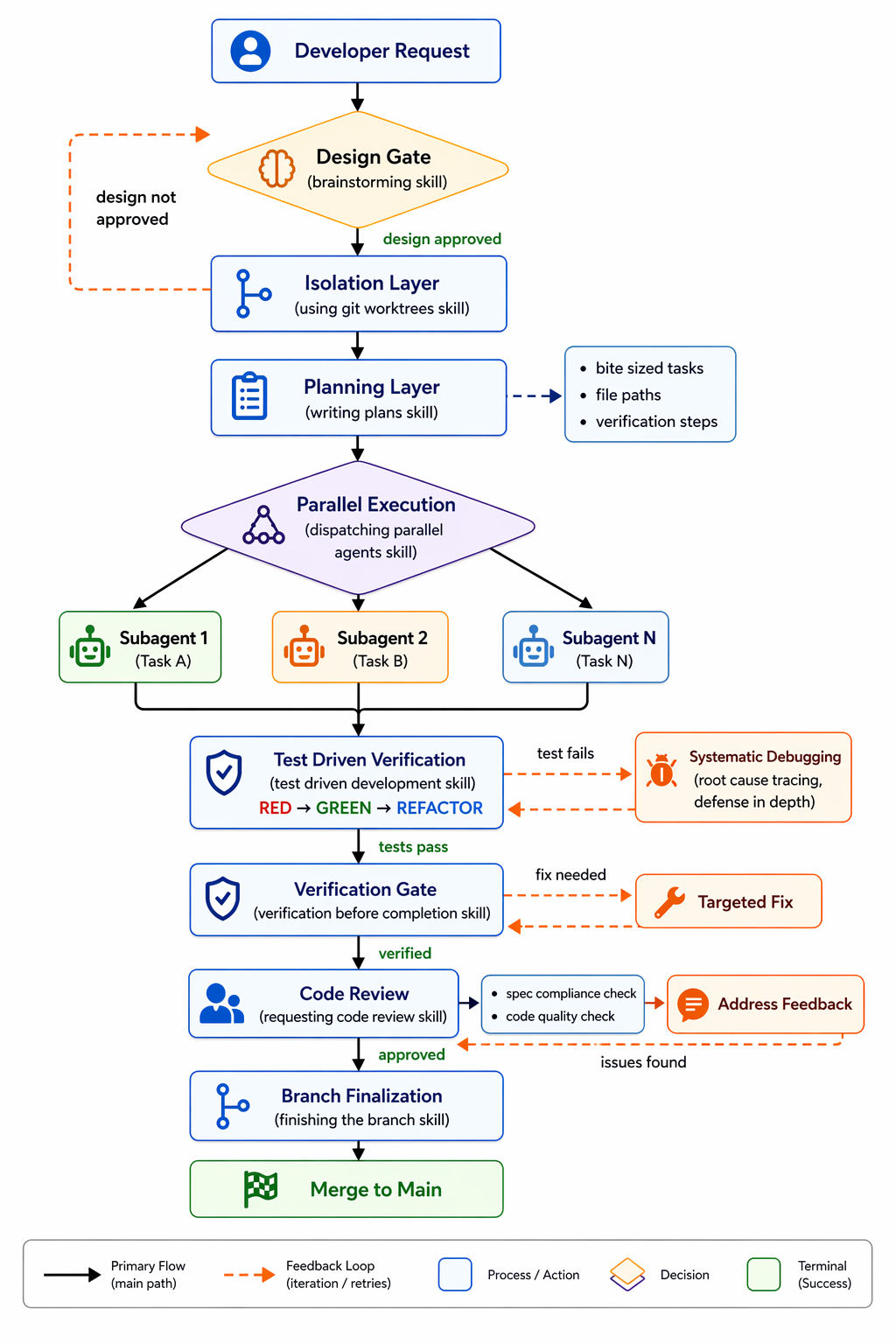
The framework enforces a structured process that mirrors how professional software teams actually work. Each stage is backed by a specific skill that defines exactly how the agent should operate at that step.
Stage 1: Mandatory Design Gate (Brainstorming)
Before any implementation begins, the agent must run a design discussion. The brainstorming skill applies Socratic questioning to surface requirements, explore alternative approaches, present tradeoffs, and wait for explicit human approval before proceeding.
This is a hard gate, not a suggestion. No code gets written until the design is validated.
For enterprise teams, this is where you catch agents about to violate architectural standards, introduce unapproved dependencies, or build something that technically works but doesn’t fit the system.
Stage 2: Isolation via Git Worktrees
The using git worktrees skill creates an isolated execution environment for each task. Every subagent operates on its own clean branch with no risk of interfering with concurrent work.
This is the foundation for safe parallel development. Without isolation, multi-agent systems quickly create merge chaos. With it, you can delegate decomposed tasks to multiple subagents simultaneously.
Stage 3: Micro Task Planning
The writing plans skill decomposes the approved design into tasks sized at 2 to 5 minutes each. Each task includes exact file paths, complete code snippets for the change, and explicit verification steps to confirm success.
This precision is what makes subagent delegation reliable. A vague task like “add authentication” fails when handed to a fresh subagent. A specific task like “create src/auth/jwt_validator.py implementing validate_token returning UserClaims, with tests at tests/auth/test_jwt_validator.py, verifiable by running pytest tests/auth/ and confirming all pass” succeeds.
Stage 4: Subagent Driven Development
The dispatching parallel agents skill spawns fresh subagents per task. Each receives a specific assignment from the plan, no context spillover from other tasks, and a clean execution environment.
This is where throughput gains happen. Work that previously required sequential developer attention can now execute concurrently. The framework supports hours-long autonomous development loops when tasks are properly decomposed.
Stage 5: Test Driven Development
The test driven development skill enforces the RED -> GREEN -> REFACTOR cycle on every task. The agent writes a failing test first, implements only enough to make it pass, then refactors while keeping tests green.
The skill includes an anti-patterns reference listing common TDD mistakes the agent should avoid. For enterprise codebases, this ensures agents don’t ship untested code or bypass quality gates under deadline pressure.
Stage 6: Verification Before Completion
The verification before completion skill requires confirmed, working output rather than assumed completion. After implementation, the agent must actually run the tests, check the outcomes, and verify fixes work before declaring a task done.
This closes the loop between generation and validation. It’s the difference between “I wrote the code” and “I confirmed the code works.”
Stage 7: Code Review
The requesting code review skill applies a two-stage review process. First, spec compliance: does the output match the approved design? Second, code quality: does the output meet engineering standards?
Issues are reported with severity labels. The agent cannot mark work complete until both stages pass.
Translating This to Enterprise Scale
The open source framework is a starting point, not a complete enterprise solution. Here’s what you need to add.
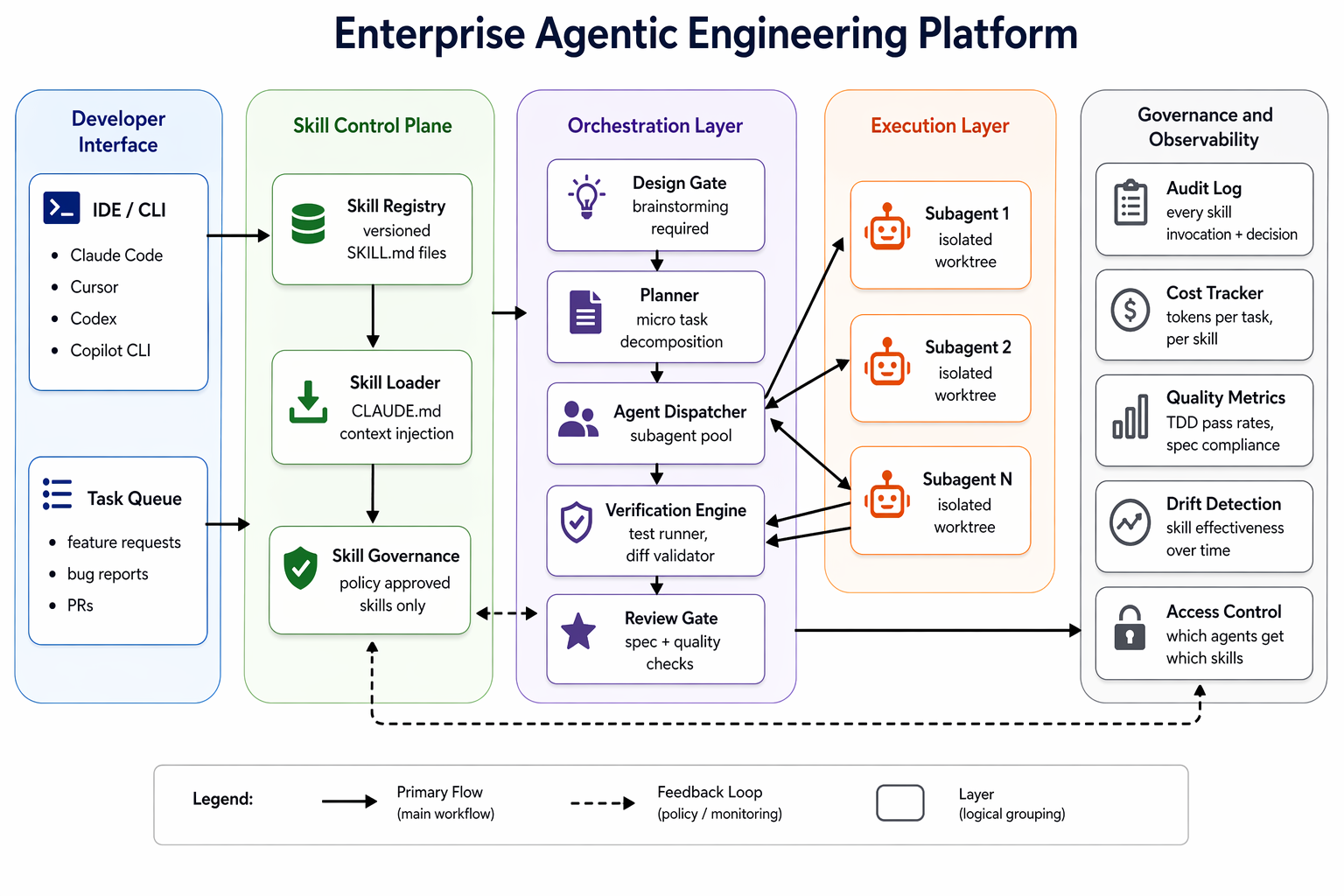
Skill Governance
In an open source context, any developer can install any skill. In enterprise settings, skills that execute shell commands, write to file systems, or interact with external APIs must go through approval before they can be invoked by agents operating on production-adjacent codebases.
The enterprise adaptation requires:
- A curated skill registry with approval status tracking
- Injection of only approved skills into agent context
- Audit logging for every skill invocation with user identity, timestamp, and task context
- Version control and peer review for skills, treating them as code artifacts
The framework includes a writing skills meta-skill that creates new skills following defined patterns. Enterprises should require new skill proposals go through architecture review before being added to the approved registry.
Parallel Agent Security
The dispatching parallel agents skill enables concurrent subagent execution, which introduces risks:
- Agents writing to shared state concurrently
- Agents consuming external API quota in parallel without rate limits
- Agents executing with more privilege than required for the task
Mitigations include:
- Enforcing worktree isolation at the infrastructure level, not just through skill guidance
- Applying rate limiting to all external API calls made by agents
- Using short-lived, scoped credentials per subagent session
- Implementing a supervisor agent that monitors parallel execution and can halt on anomaly
Memory and Context Isolation
The framework’s use of fresh subagents per task is itself a memory isolation strategy. Each subagent starts clean, with only the task definition and required context in its window.
This prevents context pollution between unrelated tasks, but it also means important shared context must be explicitly encoded in the plan. You need a context contract for each task type that specifies exactly which context is required, where it comes from, and how it is versioned.
Operationalization Blueprint
CI/CD for Skills
Skills are behavioral code. Apply the same rigor to them as application code.
Structure your skill registry like this:
skill-registry/
approved/
brainstorming@v2.1.md
writing-plans@v1.4.md
test-driven-development@v3.0.md
candidates/
new-skill-proposal.md
deprecated/
old-skill@v1.0.md (retained for audit)Pipeline stages:
- Propose new skill via pull request
- Automated linting: does it follow the
SKILL.mdformat? - Human review: architecture and security validation
- Canary deployment: test on non-critical tasks first
- Metrics gate: check TDD pass rate and token cost before promoting
- Promotion to approved registry
Evaluation Metrics
Measuring agent quality requires both task-level and program-level metrics.
Per task metrics:
- Brainstorm to implementation cycle time
- Number of plan revisions before approval
- Test pass rate on first attempt
- Verification failures caught before code review
- Spec compliance score at code review
Program level metrics:
- Tasks completed autonomously versus tasks requiring human intervention
- Rework rate (tasks returned after review)
- Cost per successfully merged change
- Skill trigger accuracy (was the right skill invoked for the task type?)
Token Cost Management
When agents reference structured skills instead of reasoning from scratch, token efficiency improves measurably. Skill coverage becomes a cost lever. The more task types covered by approved skills, the lower the per-task token cost.
Track cost per task by skill coverage status:
- Skill-covered tasks should trend lower over time
- Uncovered task types surface candidates for new skill development
Tradeoffs and Decision Framework
The Superpowers pattern sits between two poles: methodology as plugin versus fully autonomous agent.
The framework documentation is explicit about this: the overhead does not pay off for simple tasks or exploratory work. The design gate and planning stages add real latency. Profile your task types and apply the full methodology only where quality and consistency gains justify the overhead.
Build vs Adopt
You have three options for implementing an enterprise skill stack:
- Adopt Superpowers directly: Fast start, community maintained, broad platform support
- Fork and extend: Maintain internal additions while tracking upstream
- Build from scratch: Full control, maximum integration depth
My recommendation: adopt the framework as a foundation and fork only when enterprise-specific governance patterns cannot be layered on top. The skill format (SKILL.md) is a simple, portable standard. Interoperability with community skills is a durable advantage.
Anti Patterns to Avoid
Skipping the design gate under schedule pressure. The brainstorming stage is where requirements mismatches are caught at zero cost. Bypassing it to move faster is the fastest path to expensive rework.
Over delegating to subagents without plan precision. Vague micro tasks are the primary source of subagent failures. If the plan doesn’t include exact file paths and verification steps, subagent output quality degrades significantly.
Installing unapproved skills in production agents. Community skills are not vetted for enterprise security or compliance contexts. An approved skill registry is not optional overhead. It’s the governance boundary.
Measuring agent performance by lines of code generated. The correct measure is verified, reviewed, merged output. Token spend and code volume are inputs. Quality outcomes are the metric.
Using the full methodology for all tasks. Applying brainstorming, worktrees, planning, parallel agents, TDD, and review to a one-line bug fix adds cost and latency without proportional benefit. Right-size the workflow to the task risk level.
No drift detection on skill effectiveness. Skills that worked well at version 1 may degrade as models update or codebases evolve. Without periodic effectiveness measurement, skill quality decays silently.
What This Means for Enterprise Architects
The enterprise AI coding conversation has spent too long focused on which model to use. The Superpowers framework and the broader community building on it are pointing at a more important question: what workflow architecture governs how the model operates?
A 157,000-star open source project built entirely on SKILL.md behavioral guides is a signal worth paying attention to. The pattern it encodes (design gates, isolation, micro-task planning, subagent delegation, TDD enforcement, two-stage review) is a working implementation of engineering discipline applied to AI agents.
Before investing more in model capability, invest in building and governing the behavior layer that makes your agents reliable. The model is one component. The workflow control plane is the product.